











-
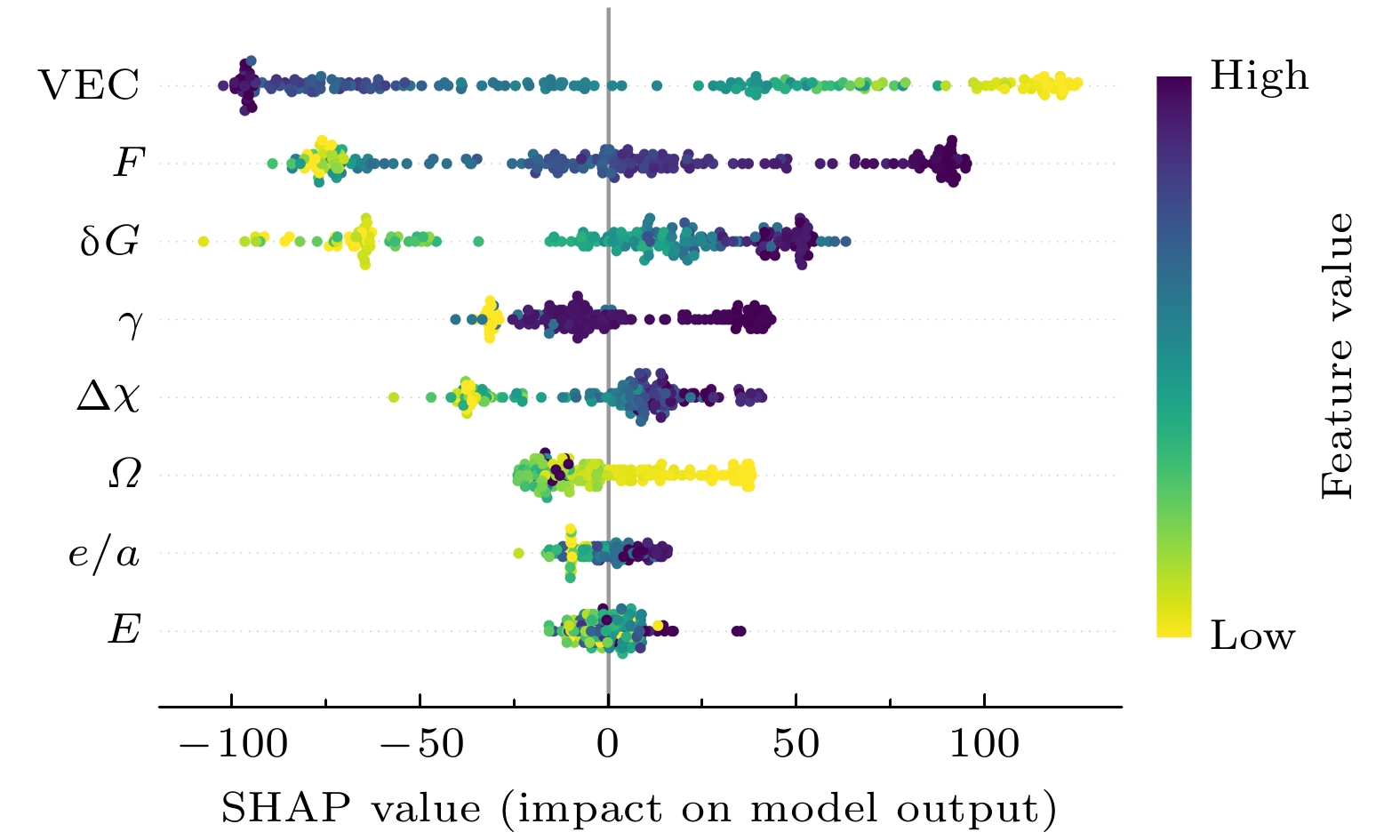
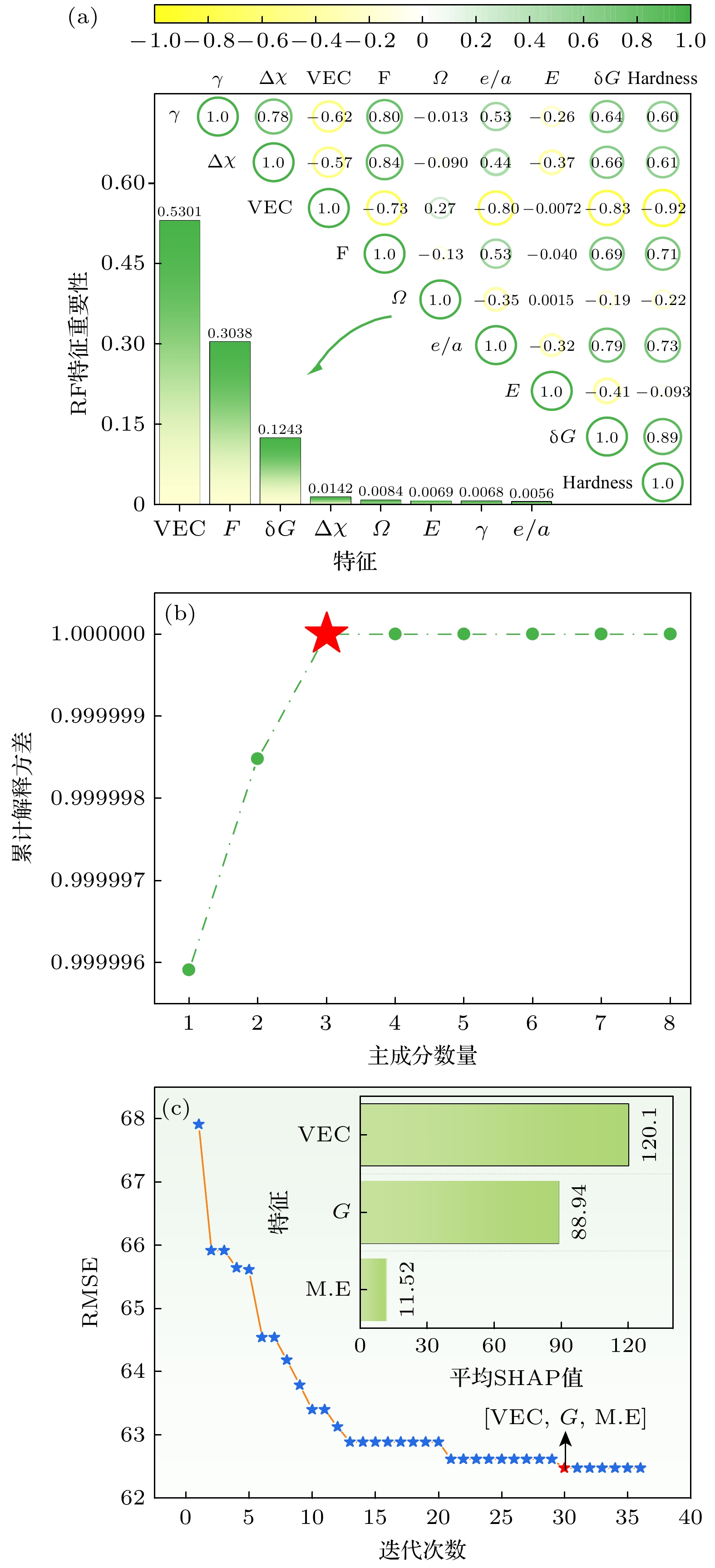
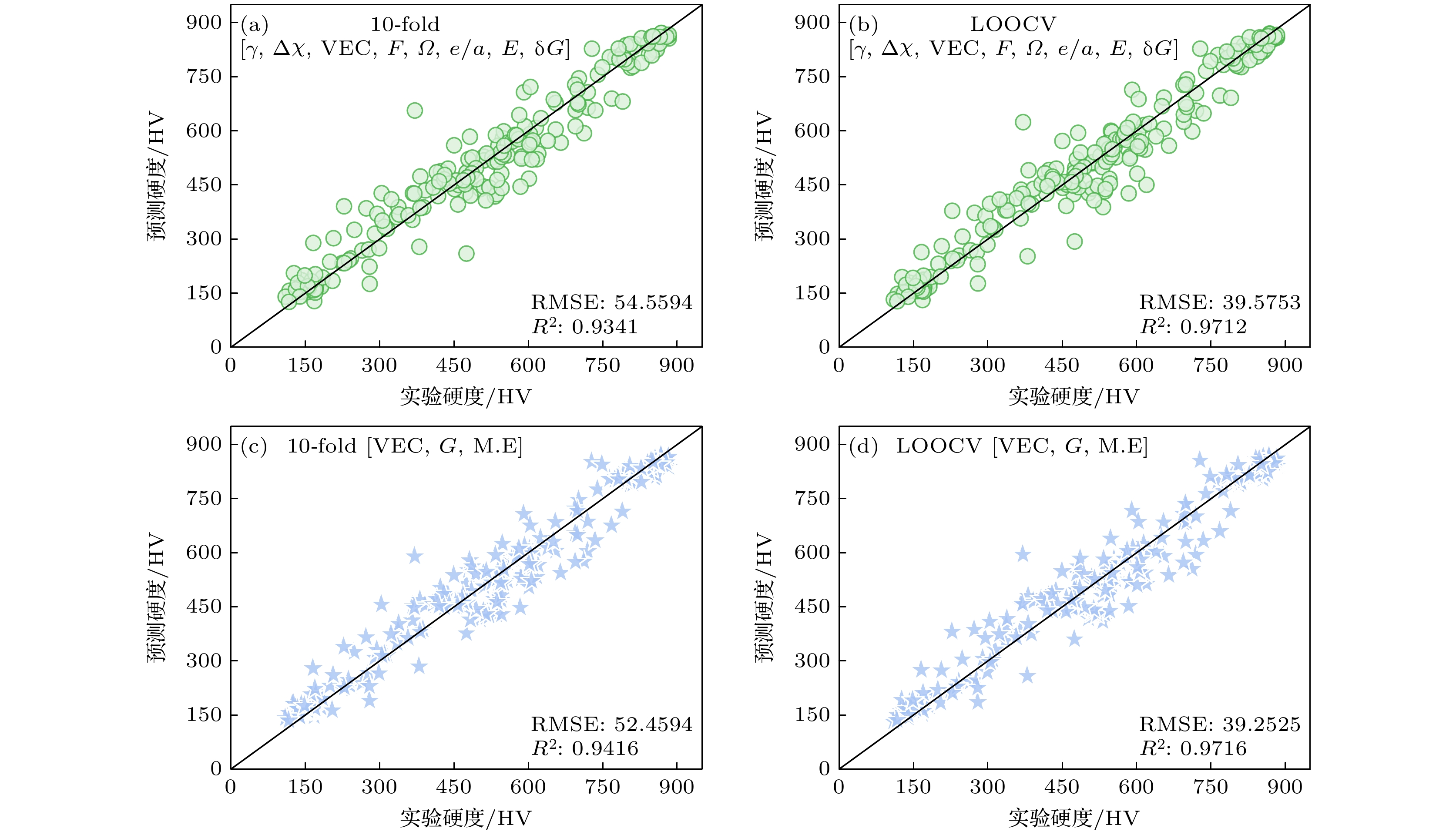
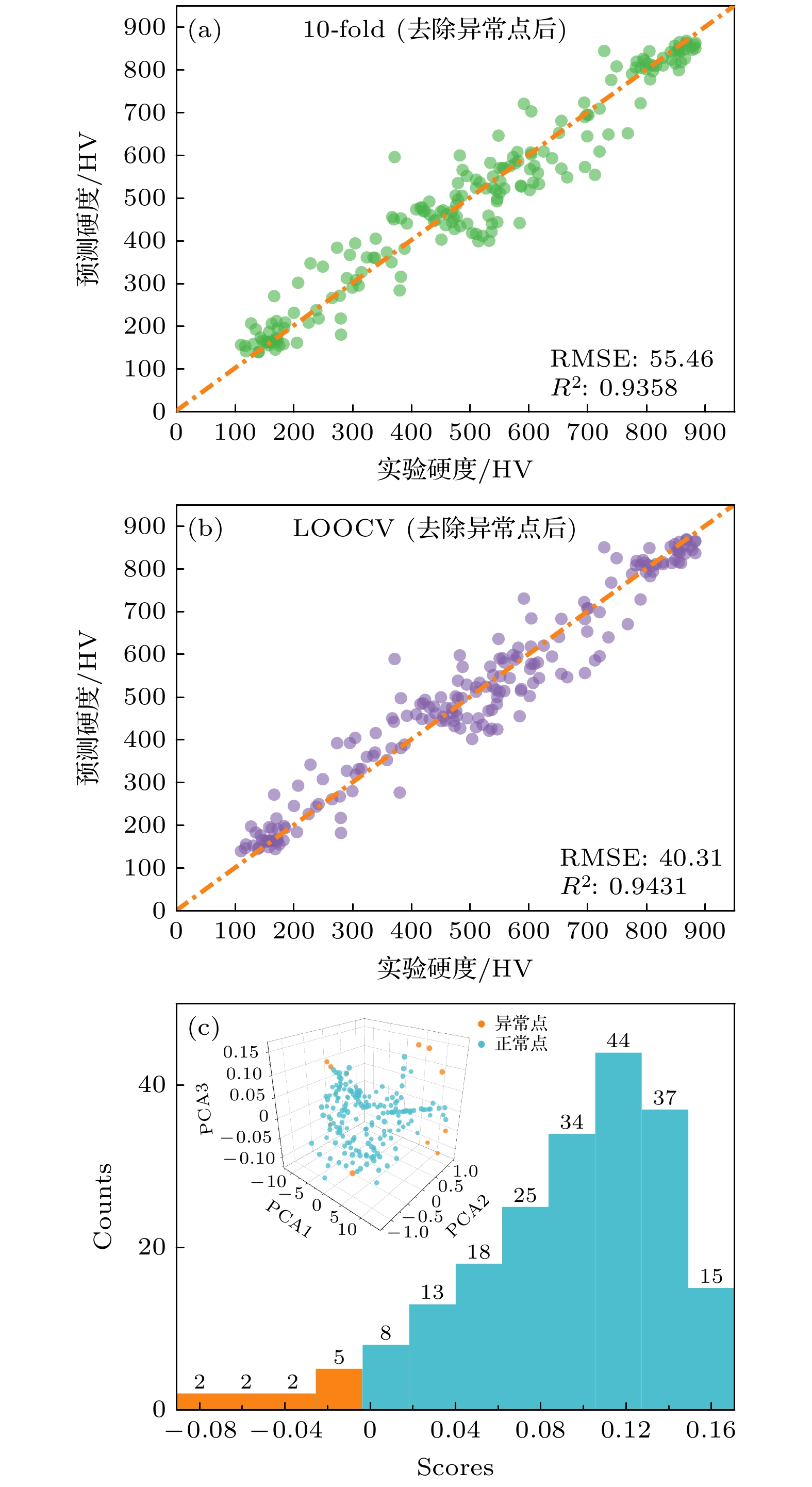
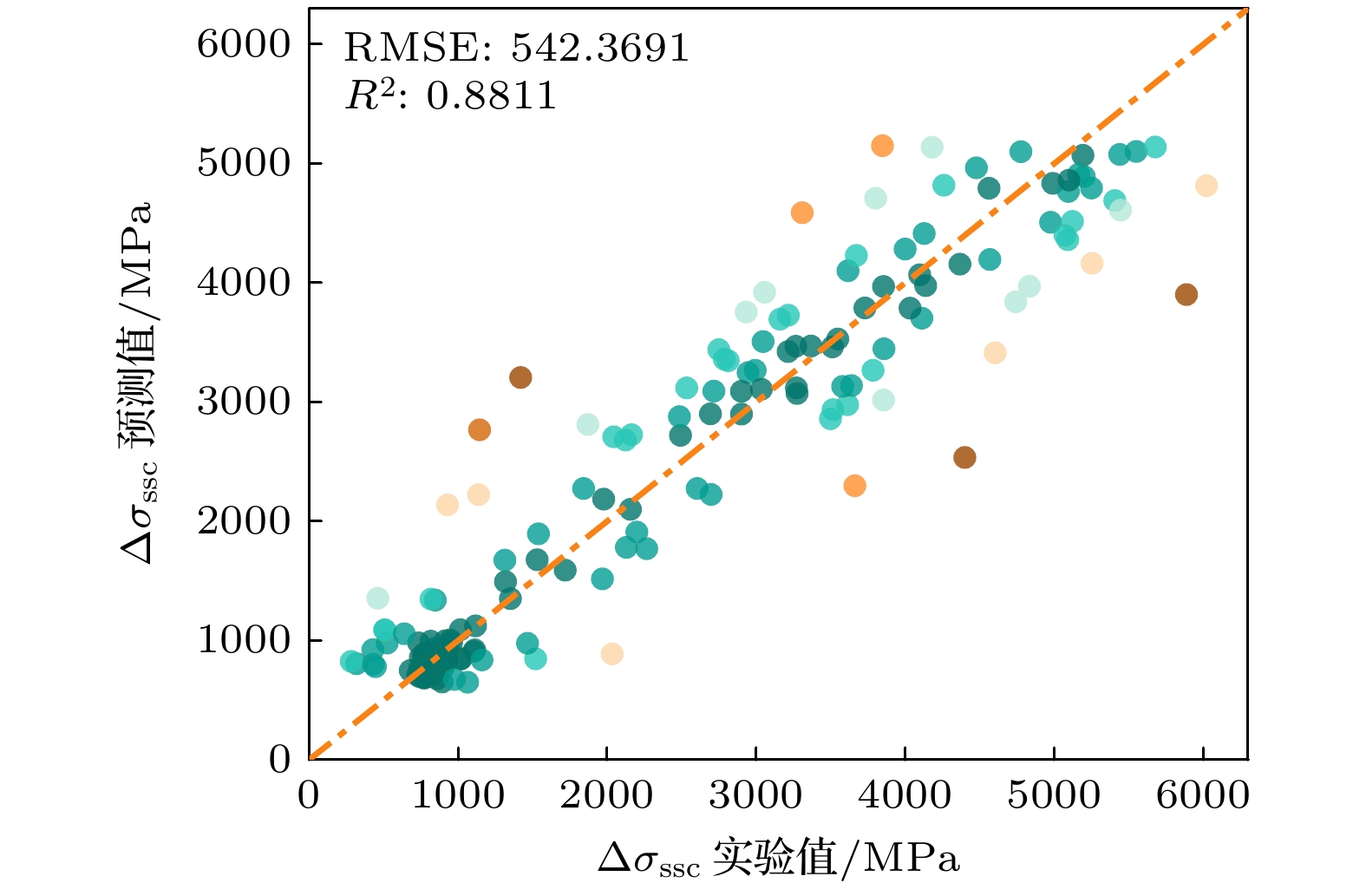
Traditional material calculation methods, such as first principles and thermodynamic simulations, have accelerated the discovery of new materials. However, these methods are difficult to construct models flexibly according to various target properties. And they will consume many computational resources and the accuracy of their predictions is not so high. In the last decade, data-driven machine learning techniques have gradually been applied to materials science, which has accumulated a large quantity of theoretical and experimental data. Machine learning is able to dig out the hidden information from these data and help to predict the properties of materials. The data in this work are obtained from the published references. And several performance-oriented algorithms are selected to build a prediction model for the hardness of high entropy alloys. A high entropy alloy hardness dataset containing 19 candidate features is trained, tested, and evaluated by using an ensemble learning algorithm: a genetic algorithm is selected to filter the 19 candidate features to obtain an optimized feature set of 8 features; a two-stage feature selection approach is then combined with a traditional solid solution strengthening theory to optimize the features, three most representative feature parameters are chosen and then used to build a random forest model for hardness prediction. The prediction accuracy achieves an R 2value of 0.9416 by using the 10-fold cross-validation method. To better understand the prediction mechanism, solid solution strengthening theory of the alloy is used to explain the hardness difference. Further, the atomic size, electronegativity and modulus mismatch features are found to have very important effects on the solid solution strengthening of high entropy alloys when genetic algorithms are used for implementing the feature selection. The machine learning algorithm and features are further used for predicting solid solution strengthening properties, resulting in an R 2of 0.8811 by using the 10-fold cross-validation method. These screened-out parameters have good transferability for various high entropy alloy systems. In view of the poor interpretability of the random forest algorithm, the SHAP interpretable machine learning method is used to dig out the internal reasoning logic of established machine learning model and clarify the mechanism of the influence of each feature on hardness. Especially, the valence electron concentration is found to have the most significant weakening effect on the hardness of high entropy alloys.
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40] -
材料特征 公式 材料特征 公式 材料特征 公式 Tm,Ec, VEC, $ e/a $,
$ E $, $ G $(由$ \alpha $表示)$ \displaystyle\sum _{i=1}^{n}{c}_{i}{\alpha }_{i} $ ΔSmix $ -R\displaystyle\sum _{i=1}^{n}{c}_{i}{\rm{l}}{\rm{n}}\left({c}_{i}\right) $ $ {w}^{6} $ $ {\left(\displaystyle\sum _{i=1}^{n}{c}_{i}{w}_{i}\right)}^{6} $ $ {\text{δ}}G $ $ \sqrt{\displaystyle\sum _{i=1}^{n}{c}_{i}{\left(1-\frac{{G}_{i}}{G}\right)}^{2}} $ ΔGmix $ {{{\Delta }}H}_{{\rm{m}}{\rm{i}}{\rm{x}}}-{T}_{{\rm{m}}}{{{\Delta }}S}_{{\rm{m}}{\rm{i}}{\rm{x}}} $ μ $ \dfrac{1}{2}E{\text{δ}}r $ $ {\text{δ}}r $ $ \sqrt{\displaystyle\sum _{i=1}^{n}{c}_{i}{\left(1-\frac{{r}_{i}}{r}\right)}^{2}} $ $ {{\Delta }}\chi $ $ \sqrt{\displaystyle\sum _{i=1}^{n}{c}_{i}{\left(\chi -{\chi }_{i}\right)}^{2}} $ $ \varOmega $ Tm$ \dfrac{{{{\Delta }}S}_{{\rm{m}}{\rm{i}}{\rm{x}}}}{{{{\Delta }}H}_{{\rm{m}}{\rm{i}}{\rm{x}}}} $ $ \gamma $ $ \dfrac{1-\sqrt{\dfrac{{\left(r+{r}_{{\rm{m}}{\rm{i}}{\rm{n}}}\right)}^{2}-{r}^{2}}{{\left(r+{r}_{{\rm{m}}{\rm{i}}{\rm{n}}}\right)}^{2}}}}{1-\sqrt{\dfrac{{\left(r+{r}_{{\rm{m}}{\rm{a}}{\rm{x}}}\right)}^{2}-{r}^{2}}{{\left(r+{r}_{{\rm{m}}{\rm{a}}{\rm{x}}}\right)}^{2}}}} $ $ A $ $ G{\text{δ}}{{r}}\dfrac{1+\mu }{1-\mu } $ $ \varLambda $ $ \dfrac{{{{\Delta }}S}_{{\rm{m}}{\rm{i}}{\rm{x}}}}{{\text{δ}}r} $ ΔHmix $ 4\displaystyle\sum _{i=1, j > i}^{n}{c}_{i}{c}_{j}{H}_{i{\text{-}}j}^{{\rm{m}}{\rm{i}}{\rm{x}}} $ $ F $ $ \dfrac{2 G}{1-\mu } $  DownLoad:
CSV
DownLoad:
CSV
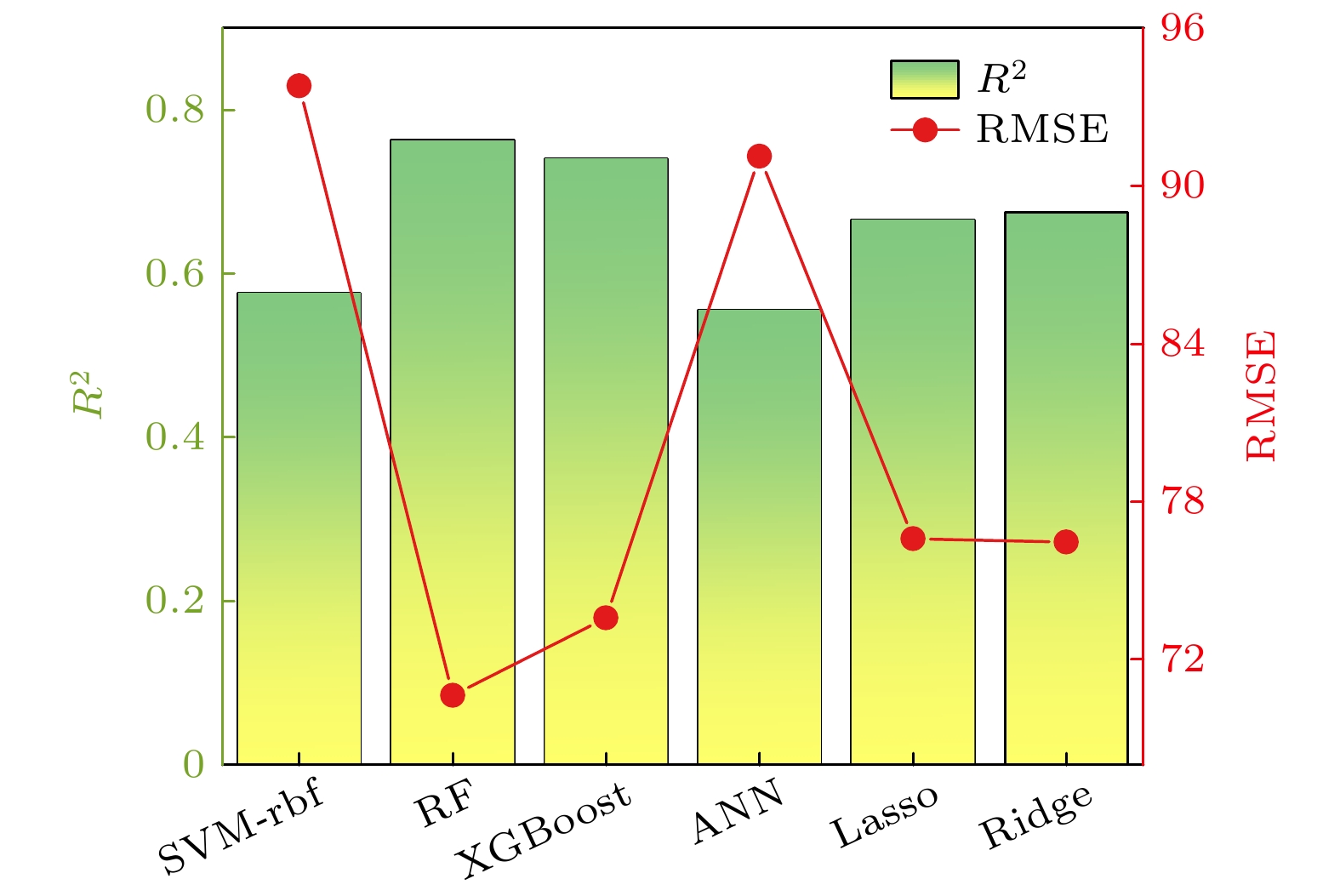
算法 超参数 SVM-rbf gamma = 1×10–7,C= 200 RF max_depth = 6, min_samples_leaf = 1, min_samples_split = 2, n_estimators = 50 XGBoost gamma = 0.1, learning_rate = 0.1, max_depth = 12, n_estimators = 100, reg_alpha = 0, reg_lambda = 0.5 ANN max_iter = 210000, hidden_layer_sizes = 16, solver = 'adam', activation = 'relu',
alpha = 0.01Lasso alpha = 1, max_iter = 10000 Ridge alpha = 0.1, max_iter = 10000 DownLoad:
CSV
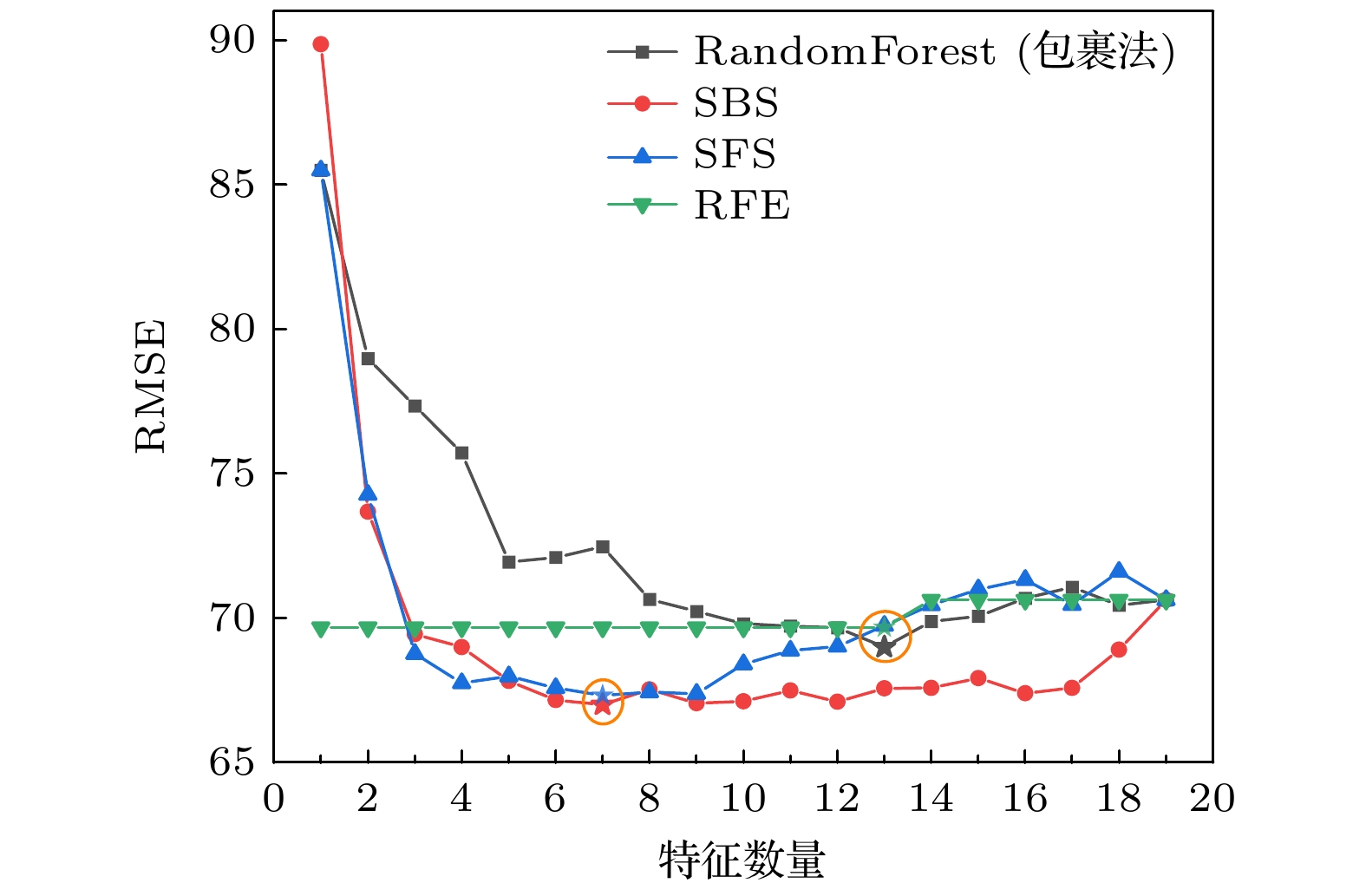
算法 优化特征组 RMSE GA γ, Δχ, VEC,F,Ω,e/a,E, δG 64.09 SFS δr,Ec, VEC, ΔHmix,Ω, E,G 67.32 SBS Δχ,Ec, VEC,Λ,w, F, δG 67.00 RFE δr,Ec, VEC, ΔSmix,Ω, Λ,E,
μ, w, G,F,A,δG69.67 RF δr, VECF,Λ,w,δG, μ, G,
A, Ec,Ω,ΔSmix, ΔHmix68.99 DownLoad:
CSV
-
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40]


 DownLoad:
DownLoad:






Catalog
Metrics
- Abstract views:3188
- PDF Downloads:141
- Cited By:0