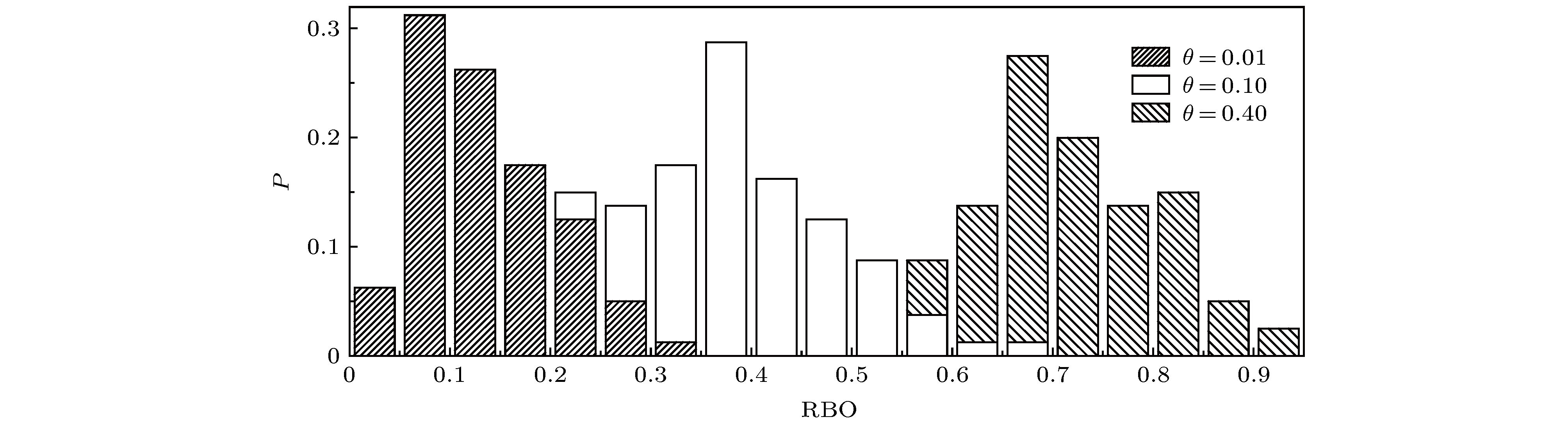
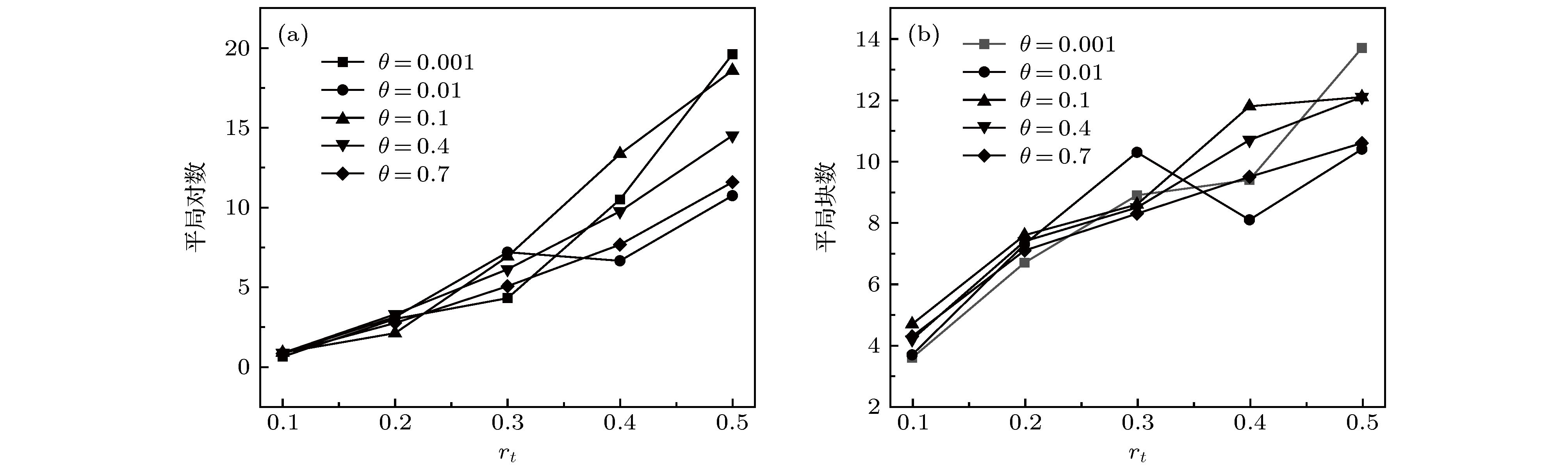
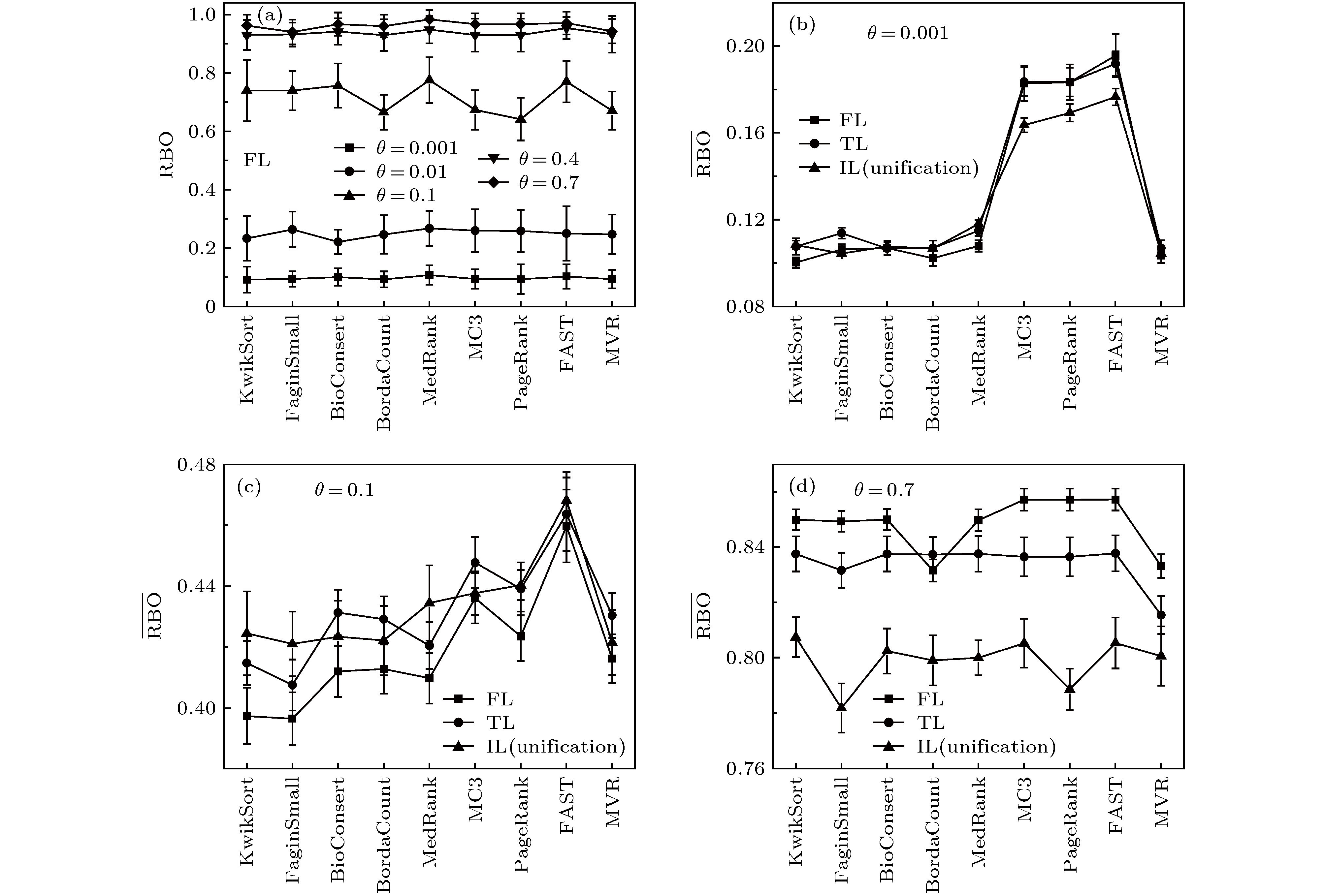
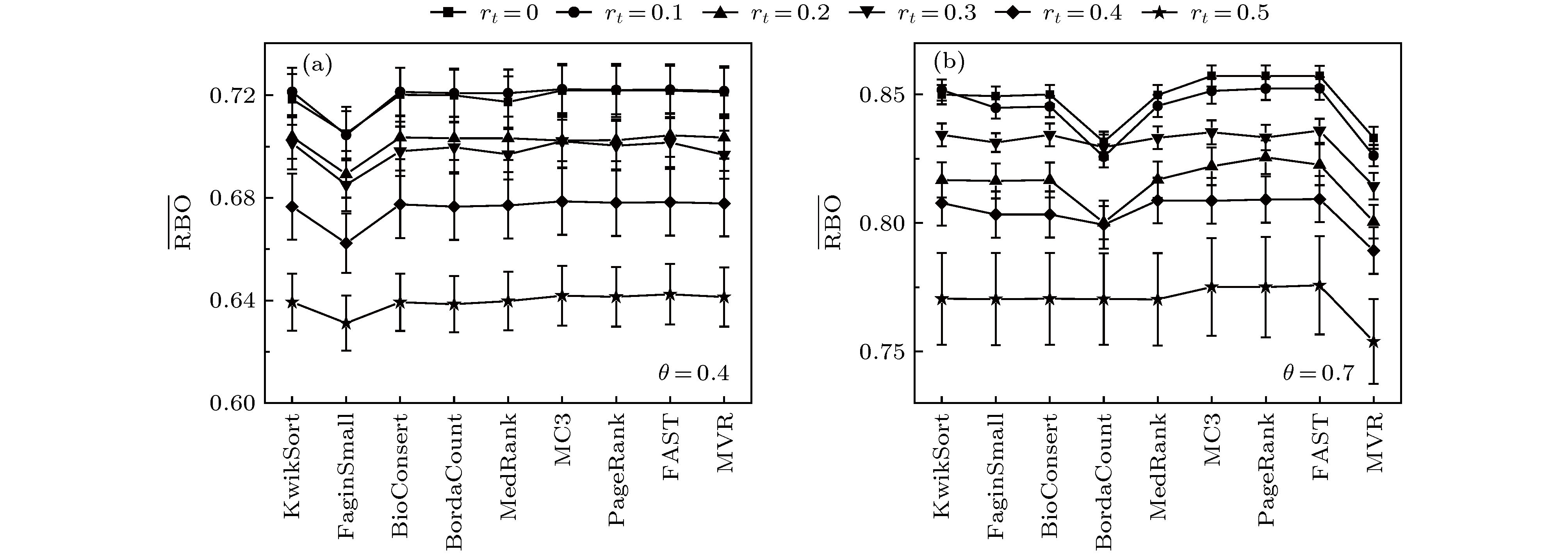
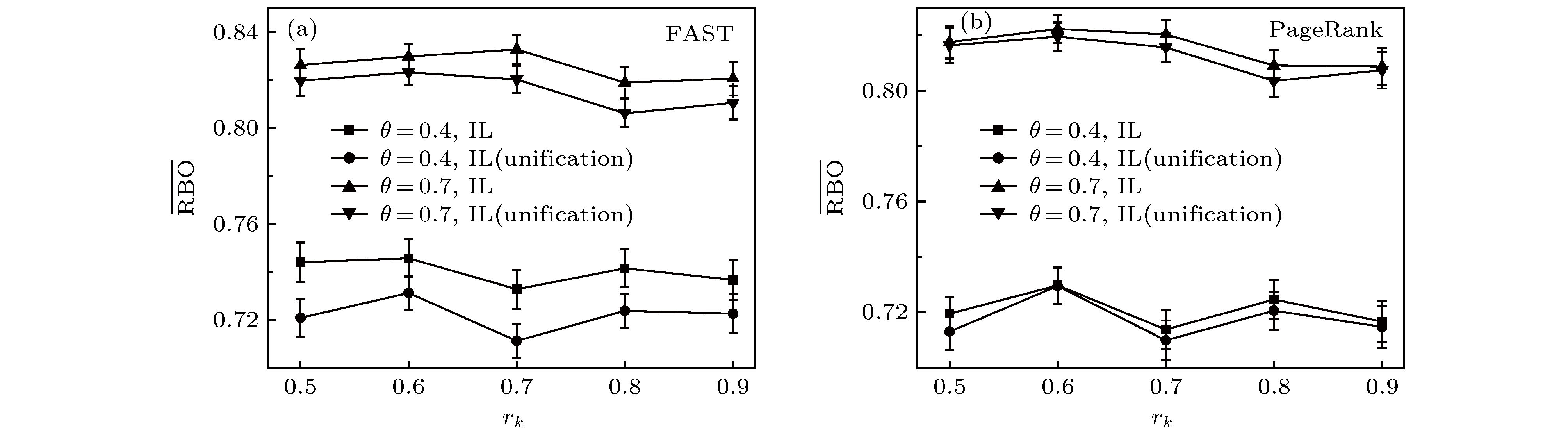
Rank aggregation aims to combine multiple rank lists into a single one, which has wide applications in recommender systems, link prediction, metasearch, proposal selection, and so on. Some existing studies have summarized and compared different rank aggregation algorithms. However, most of them cover only a few algorithms, the data used to test algorithms do not have a clear statistical property, and the metric used to quantify the aggregated results has certain limitations. Moreover, different algorithms all claim to be superior to existing ones when proposed, the baseline algorithms, the testing samples, and the application scenario are all different from case to case. Therefore, it is still unclear which algorithm is better for a particular task. Here we review nine rank aggregation algorithms and compare their performances in aggregating a small number of long rank lists. We assume an algorithm to generate different types of rank lists with known statistical properties and cause a more reliable metric to quantify the aggregation results. We find that despite the simplicity of heuristic algorithms, they work pretty well when the rank lists are full and have high similarities. In some cases, they can reach or even surpass the optimization-based algorithms in performance. The number of ties in the list will reduce the quality of the consensus rank and increase fluctuations. The quality of aggregated rank changes non-monotonically with the number of rank lists that need to be combined. Overall, the algorithm FAST outperforms all others in three different rank types, which can sufficiently complete the task of aggregating a small number of long rank lists.















 DownLoad:
DownLoad:





