










-
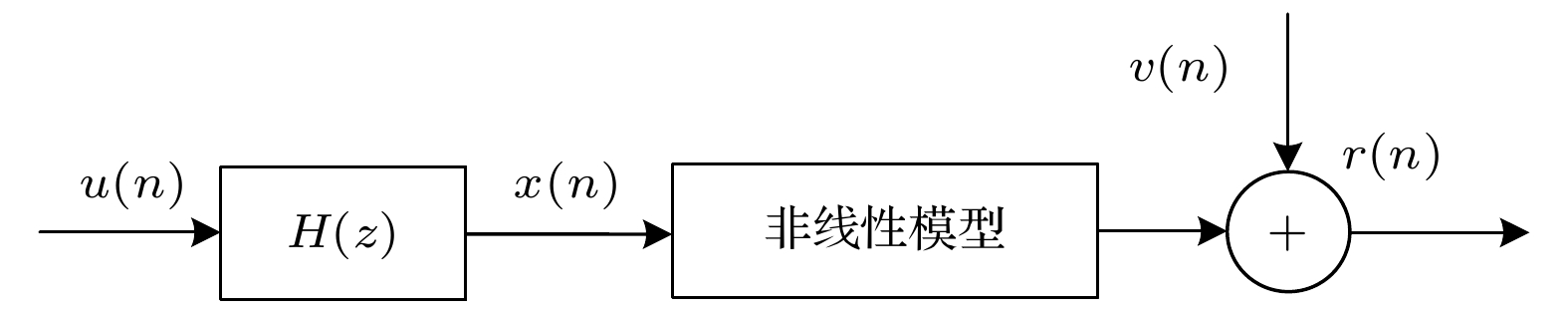
针对非线性问题, 本文将核方法和双曲正弦函数的逆相结合, 提出了鲁棒的核最小逆双曲正弦算法. 然后利用向量量化对输入空间数据进行量化, 构建出能够抑制网络规模增长的量化核最小逆双曲正弦算法, 降低了原有算法的计算复杂度, 给出了量化核最小逆双曲正弦算法的能量守恒关系和收敛条件. Mackey-Glass短时混沌时间序列预测和非线性信道均衡环境的仿真结果表明, 本文所提出的核最小逆双曲正弦算法和量化核最小逆双曲正弦算法在收敛速度、鲁棒性和计算复杂度上具有优势.
-
关键词:
- 核方法/
- 向量量化/
- 核最小逆双曲正弦算法/
- 短时混沌时间序列预测
In the last few decades, the kernel method has been successfully used in the field of adaptive filtering to solve nonlinear problems. Mercer kernel is used to map data from input space to reproducing kernel Hilbert space (RKHS) by kernel adaptive filter (KAF). In regenerated kernel Hilbert spaces, the inner product can be easily calculated by computing the so-called kernel trick. The Kernel adaptive filtering algorithm is superior to common adaptive filtering algorithm in solving nonlinear problems and nonlinear channel equalization. For nonlinear problems, a robust kernel least inverse hyperbolic sine (KLIHS) algorithm is proposed by combining the kernel method with the inverse of hyperbolic sine function.The main disadvantage of KAF is that the radial-basis function (RBF) network grows with every new data sample, which increases the computational-complexity and requires more momories. The vector quantization (VQ) has been proposed to address this problem and has been successfully applied to the current kernel adaptive filtering algorithm. The main idea of the VQ method is to compress the input space through quantization to curb the network-size growth. In this paper, vector quantization is used to quantify the input spatial data, and a quantized kernel least inverse hyperbolic sine (QKLIHS) algorithm is constructed to restrain the growth of network scale. The energy conservation relation and convergence condition of quantized kernel least inverse hyperbolic sine algorithm are given. The simulation results of Mackey-Glass short-time chaotic time series prediction and nonlinear channel equalization environment show that the proposed kernel least inverse hyperbolic sine algorithm and quantized kernel least inverse hyperbolic sine algorithm have advantages in convergence speed, robustness and computational complexity.-
Keywords:
- kernel method/
- the vector quantization/
- kernel least inverse hyperbolic sine algorithm/
- short-time chaotic time series prediction
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] -
初始化: 选择步长$ \mu $; 映射核宽h; $ {\boldsymbol{a} }(1) = 2\mu \dfrac{1}{ {\sqrt {1 + {d^4}\left( 1 \right)} } }d\left( 1 \right) $; ${\boldsymbol{C}}\left( 1 \right) = \left\{ {x\left( 1 \right)} \right\}$ 每获得一对新的样本$\left\{ {{\boldsymbol{x}}(n), {\boldsymbol{d}}(n)} \right\}$时 1) 计算输出值: $y\left( n \right) = \displaystyle\sum\nolimits_{j = 1}^{n - 1} { { {\boldsymbol{a} }_j}\left( n \right)\kappa \left( { {\boldsymbol{x} }\left( j \right), {\boldsymbol{x} }\left( n \right)} \right)}$ 2) 计算误差: $ e(n) = d(n) - y\left( n \right) $ 3) 添加存储新中心: ${\boldsymbol{C}}\left( n \right) = \left\{ {{\boldsymbol{C}}\left( {n - 1} \right), {\boldsymbol{x}}\left( n \right)} \right\}$ 4) 更新系数:
${~} \qquad \qquad {\boldsymbol{a} }(n) = \Big\{ { {\boldsymbol{a} }(n-1), 2\mu \dfrac{1}{ {\sqrt {1 + {e^4} (n)} } }e (n)} \Big\}$停止循环  下载:
导出CSV
下载:
导出CSV
初始化: 选择步长$ \mu $; 映射核宽$ h $; 量化阈值$ \gamma $; $ {\boldsymbol{a} }(1) = 2\mu \dfrac{1}{ {\sqrt {1 + {d^4}\left( 1 \right)} } }d\left( 1 \right) $; ${\boldsymbol{C} }\left( 1 \right) = \left\{ { {\boldsymbol{x} }\left( 1 \right)} \right\}$ 每获得一对新的样本$\left\{ {{\boldsymbol{x}}(n), d(n)} \right\}$时 1) 计算输出值: $y\left( n \right) = \displaystyle\sum\limits_{j = 1}^{n - 1} { { {\boldsymbol{a} }_j}\left( n \right)\kappa \left( { {\boldsymbol{x} }\left( j \right), {\boldsymbol{x} }\left( n \right)} \right)}$ 2) 计算误差: $ e(n) = d(n) - y\left( n \right) $ 3) 计算${\boldsymbol{x} }\left( n \right)$与当前字典${\boldsymbol{C} }\left( {n - 1} \right)$的欧几里得距离: ${\rm{dis} }({ {\boldsymbol{x} }(n), {(\boldsymbol{C} }({n - 1})}) = \mathop {\min }\limits_{1 \leqslant j \leqslant {\rm{size} }({ {\boldsymbol C } ({n - 1})})} \left\| { {\boldsymbol{x} }( n) - { {\boldsymbol{C} }_j}({n - 1})} \right\|$ 4) 若${\rm{dis}}\left( { {\boldsymbol{x} }\left( n \right), {\boldsymbol{C} }\left( {n - 1} \right)} \right) > \gamma$, 更新字典: ${ {\boldsymbol{x} }_{\rm{q}}}\left( n \right) = {\boldsymbol{x} }\left( n \right)$, ${\boldsymbol{C} }\left( n \right) = \left\{ { {\boldsymbol{C} }\left( {n - 1} \right), { {\boldsymbol{x} }_{\rm{q}}}\left( n \right)} \right\}$ 添加相应系数向量$ {\boldsymbol{a} }\left( n \right) = \left[ { {\boldsymbol{a} }\left( {n - 1} \right), 2\mu \dfrac{1}{ {\sqrt {1 + {e^4}\left( n \right)} } }e\left( n \right)} \right] $ 否则, 保持字典不变: ${\boldsymbol{C} }\left( n \right) = {\boldsymbol{C} }\left( {n - 1} \right)$ 计算与当前数据最近字典元素的下标$j * = \mathop {\arg \min }\limits_{1 \leqslant j \leqslant {\rm{size}}\left( { {\boldsymbol{C} }\left( {n - 1} \right)} \right)} \left\| { {\boldsymbol{x} }\left( n \right) - { {\boldsymbol{C} }_j}\left( {n - 1} \right)} \right\|$ 将${ {\boldsymbol{C} }_{j * } }\left( {n - 1} \right)$作为当前数据的量化值, 并更新系数向量: ${ {\boldsymbol{x} }_{\rm{q}}}\left( n \right) = { {\boldsymbol{C} }_{j * } }\left( {n - 1} \right)$, $ { {\boldsymbol{a} }_{j * } }\left( n \right) = { {\boldsymbol{a} }_{j * } }\left( {n - 1} \right) + 2\mu \dfrac{1}{ {\sqrt {1 + {e^4}\left( n \right)} } }e\left( n \right) $ 停止循环 下载:
导出CSV
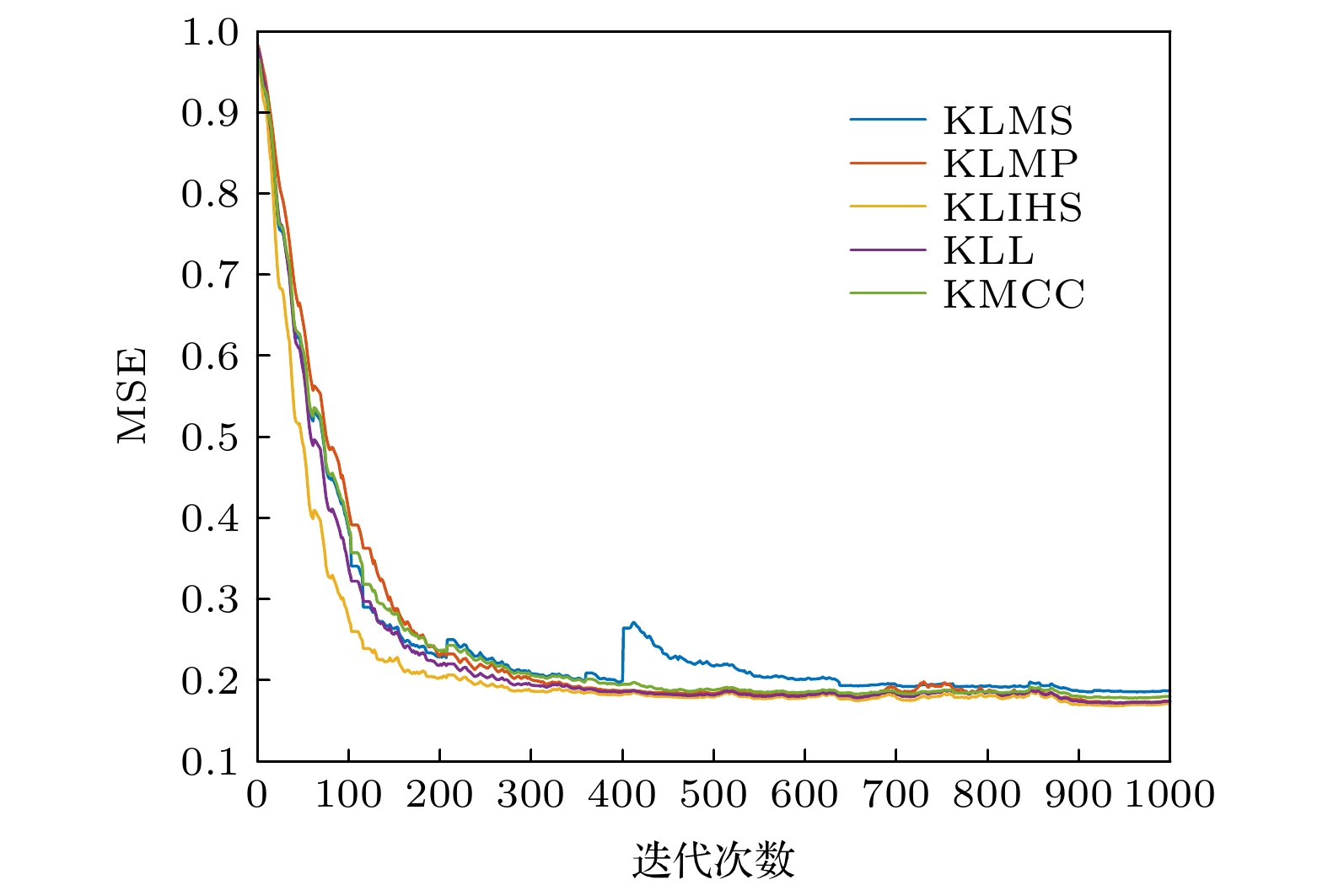
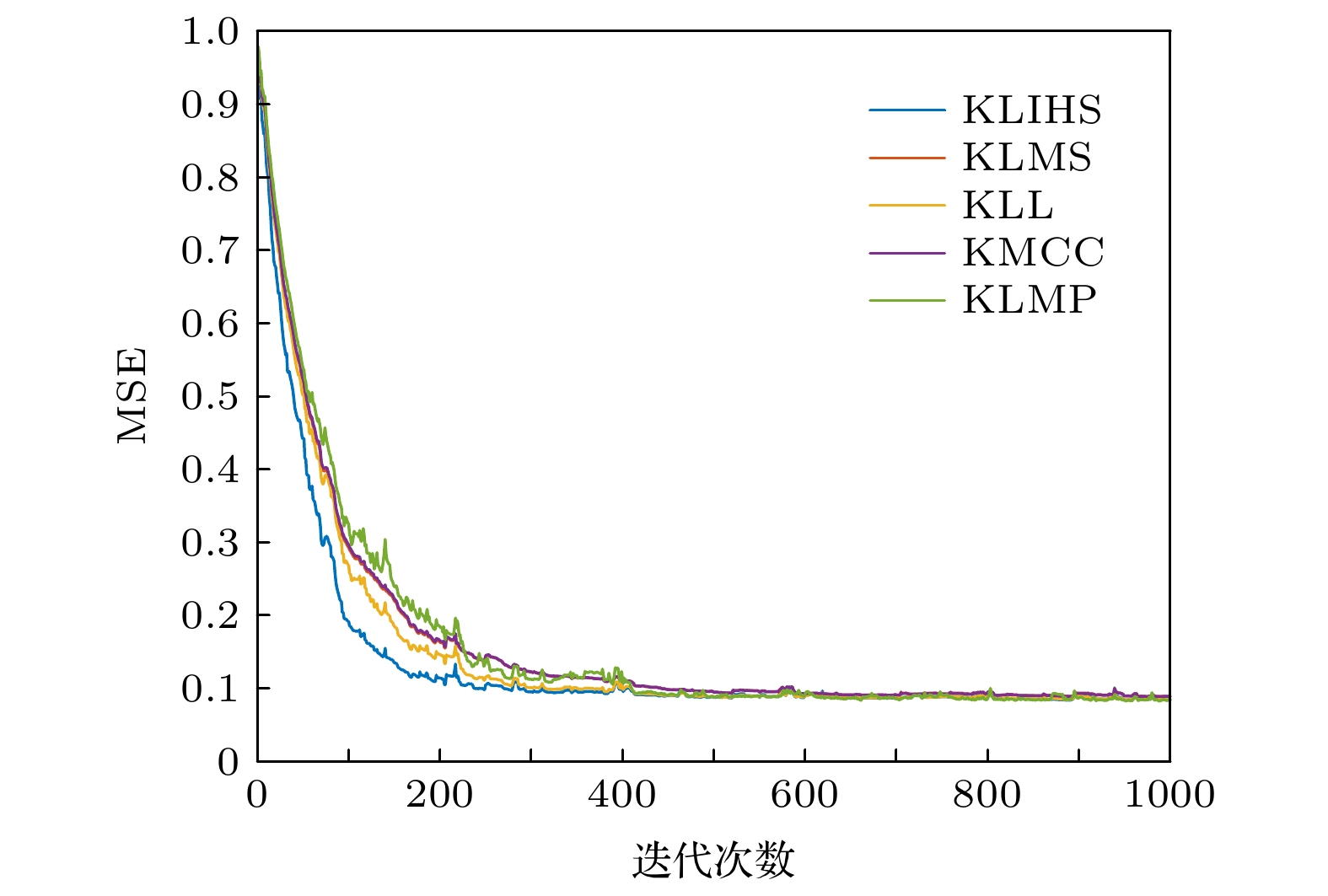
算法 均值$ \pm $偏差 KLMS $ 0.2256 \pm 0.1082 $ KMCC $ 0.1847 \pm 0.0034 $ KLMP $ 0.1831 \pm 0.0061 $ KLL $ 0.1807 \pm 0.0047 $ KLIHS $ 0.1773 \pm 0.0045 $ 下载:
导出CSV
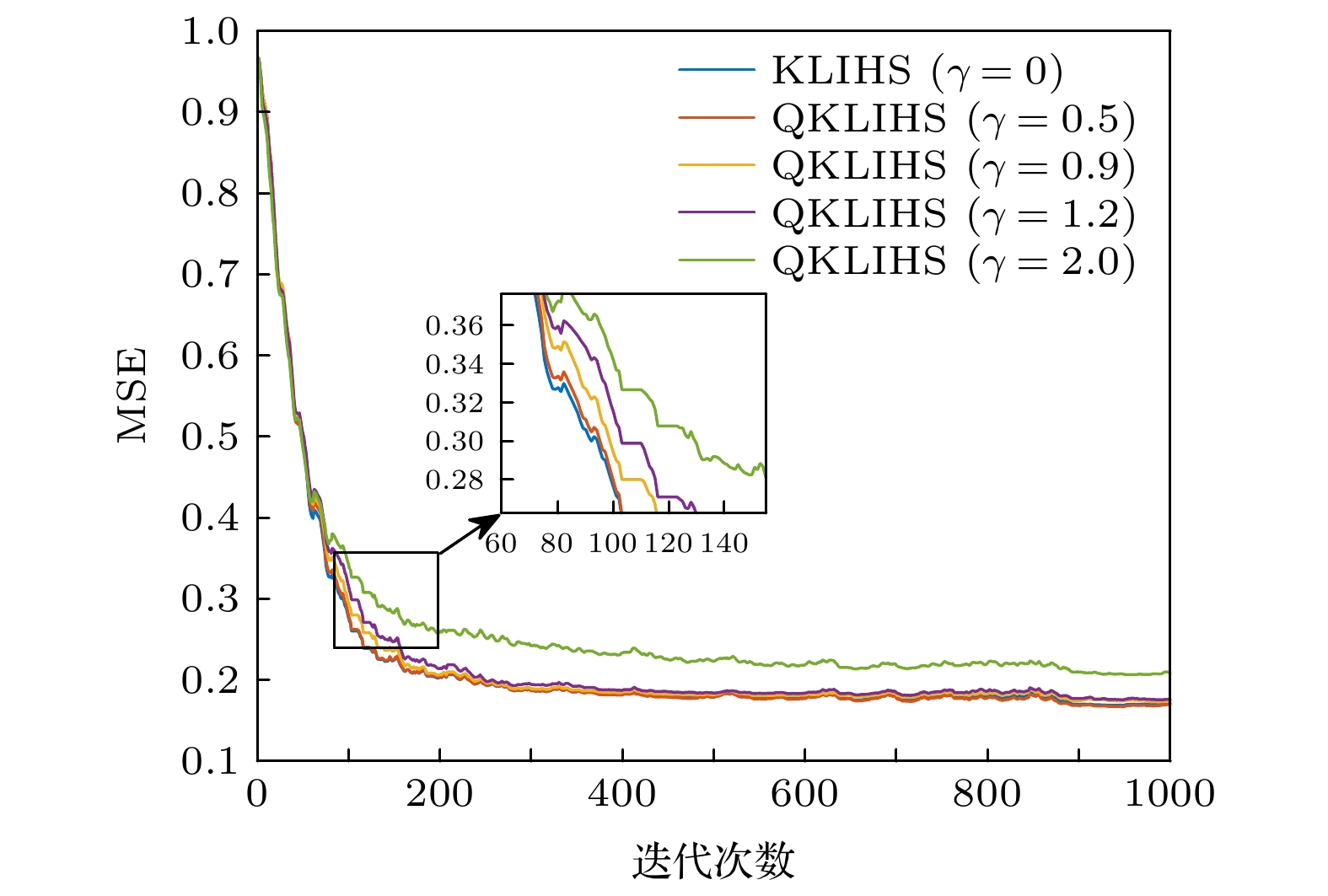
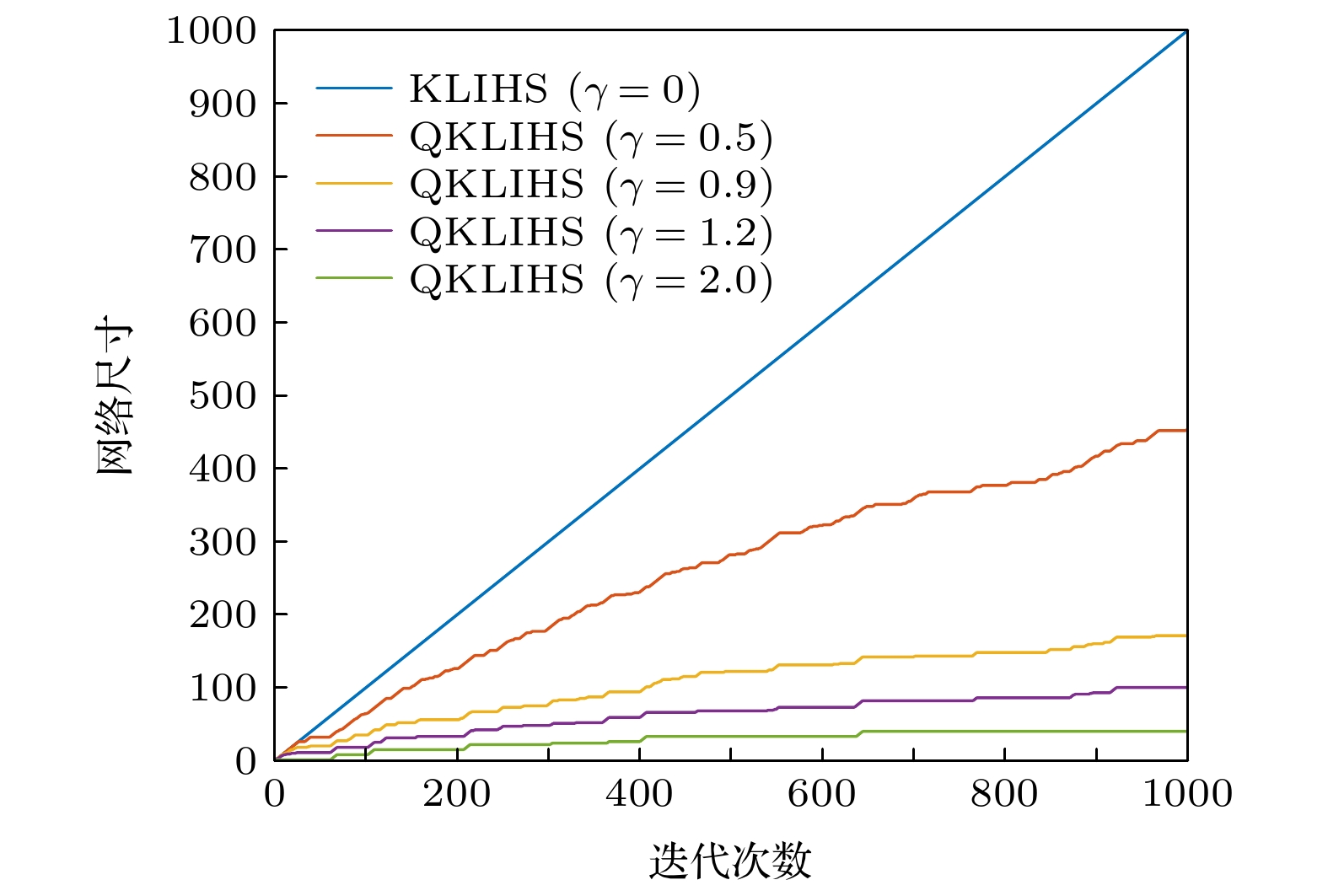
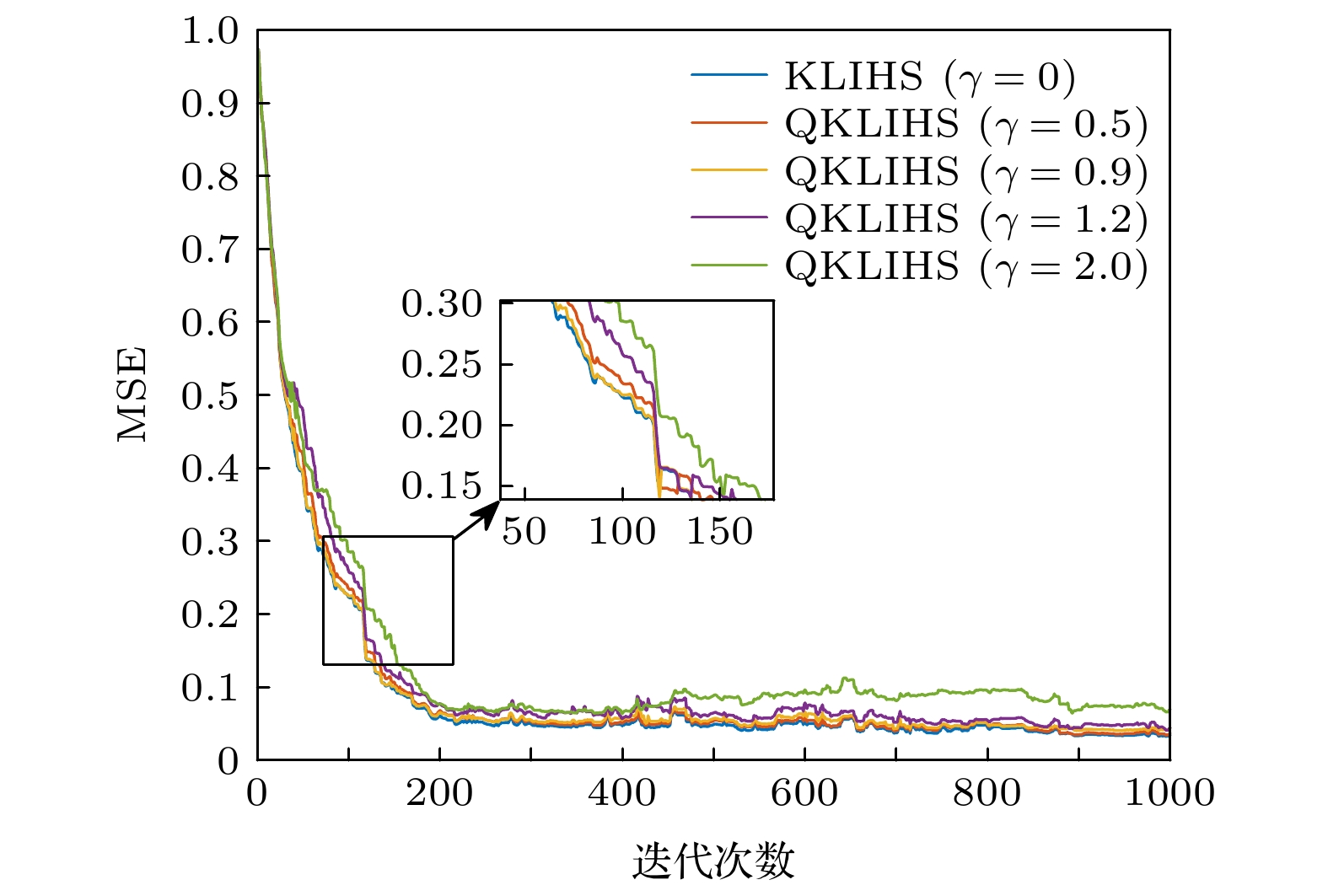
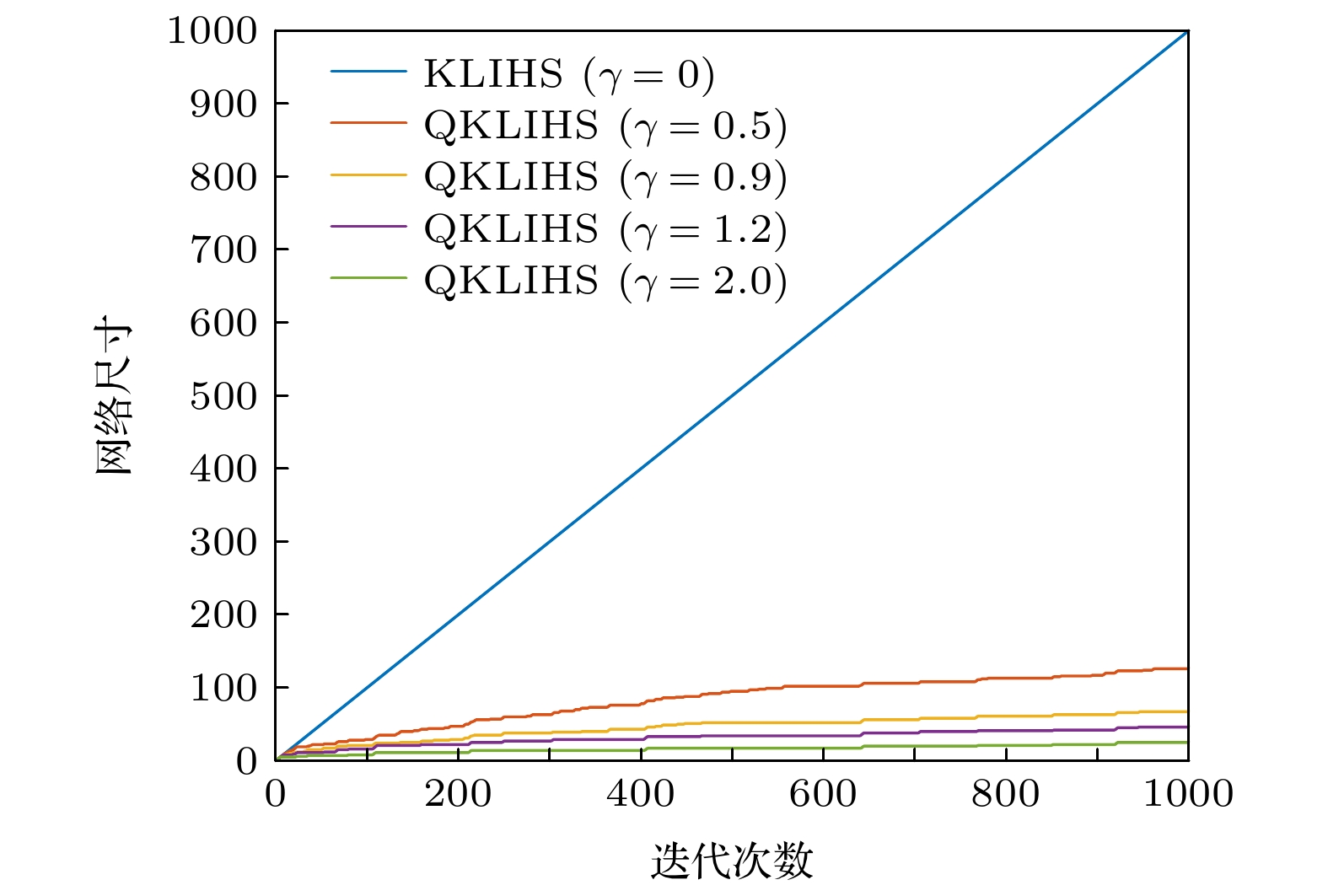
量化阈值 误差均值$ \pm $偏差 网络尺寸 0 $ 0.1738 \pm 0.0046 $ 1000 0.5 $ 0.1759 \pm 0.0050 $ 454 0.9 $ 0.1793 \pm 0.0041 $ 172 1.2 $ 0.1820 \pm 0.0045 $ 101 2.0 $ 0.2149 \pm 0.0056 $ 41 下载:
导出CSV
量化阈值 误差均值$ \pm $偏差 网络尺寸 0 $ 0.0422 \pm 0.0060 $ 1000 0.5 $ 0.0454 \pm 0.0065 $ 127 0.9 $ 0.0489 \pm 0.0063 $ 68 1.2 $ 0.0560 \pm 0.0080 $ 47 2.0 $ 0.0866 \pm 0.0095 $ 26 下载:
导出CSV
-
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22]

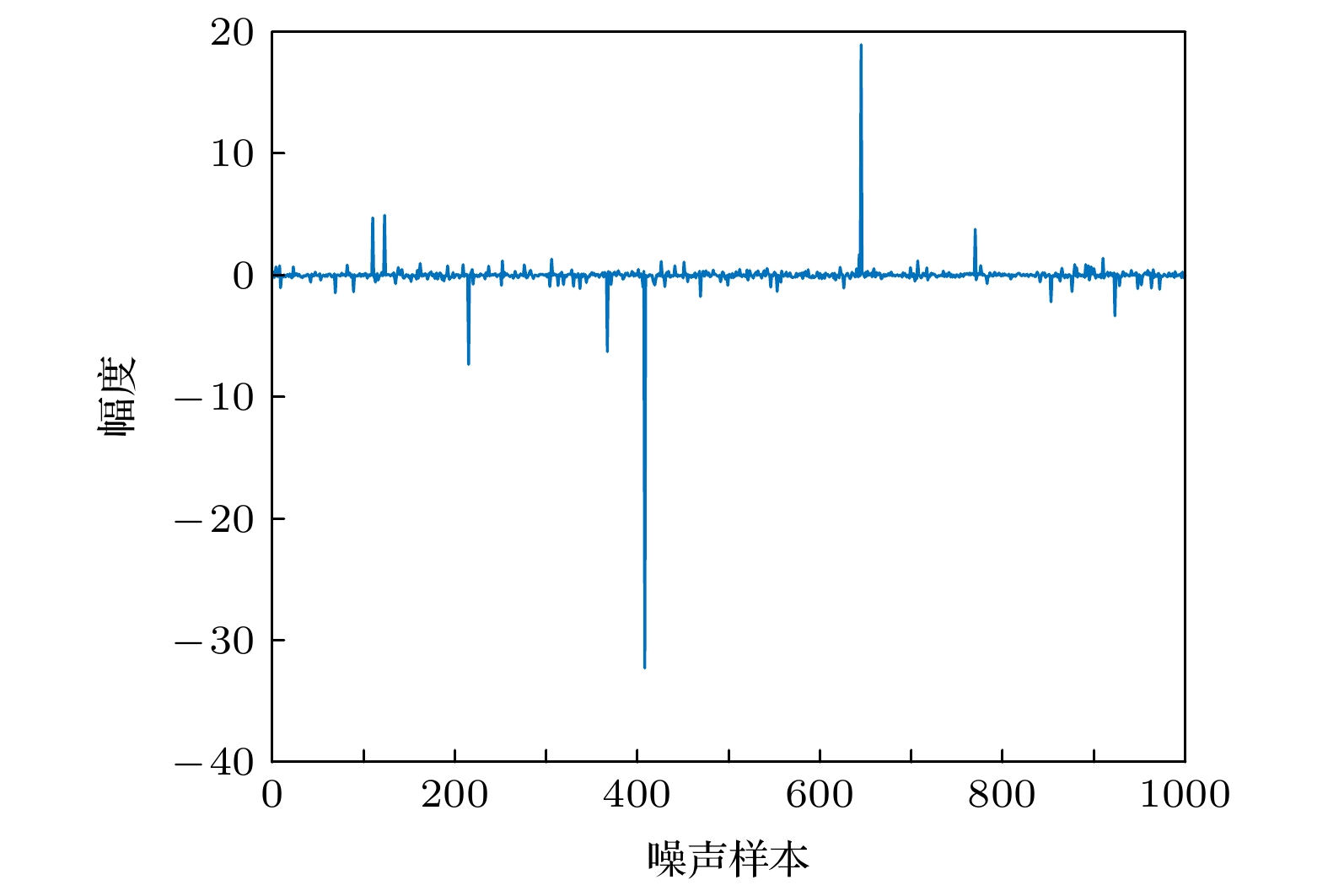
 下载:
下载:
计量
- 文章访问数:2678
- PDF下载量:31
- 被引次数:0